

How Claude Mythos Replaced My 600-Word Stock Analysis Prompt with One Line
A stock crashed 18% in the tech selloff. Claude Mythos ran the whole research workflow from four plain instructions and found a blind spot in my own rules.

Nobody teaches you what to do on the day your stock breaks.
There are thousands of newsletters about investing. I write one of them. We teach frameworks, checklists, workflows. All of it built on problems someone already solved.
Then a week like this one arrives.
Broadcom, one of the ten largest companies in America, is down 8.5 percent over the past month. That number sounds manageable until you see how it happened. Almost all of it came in the last five trading days, a drop of roughly 20 percent.
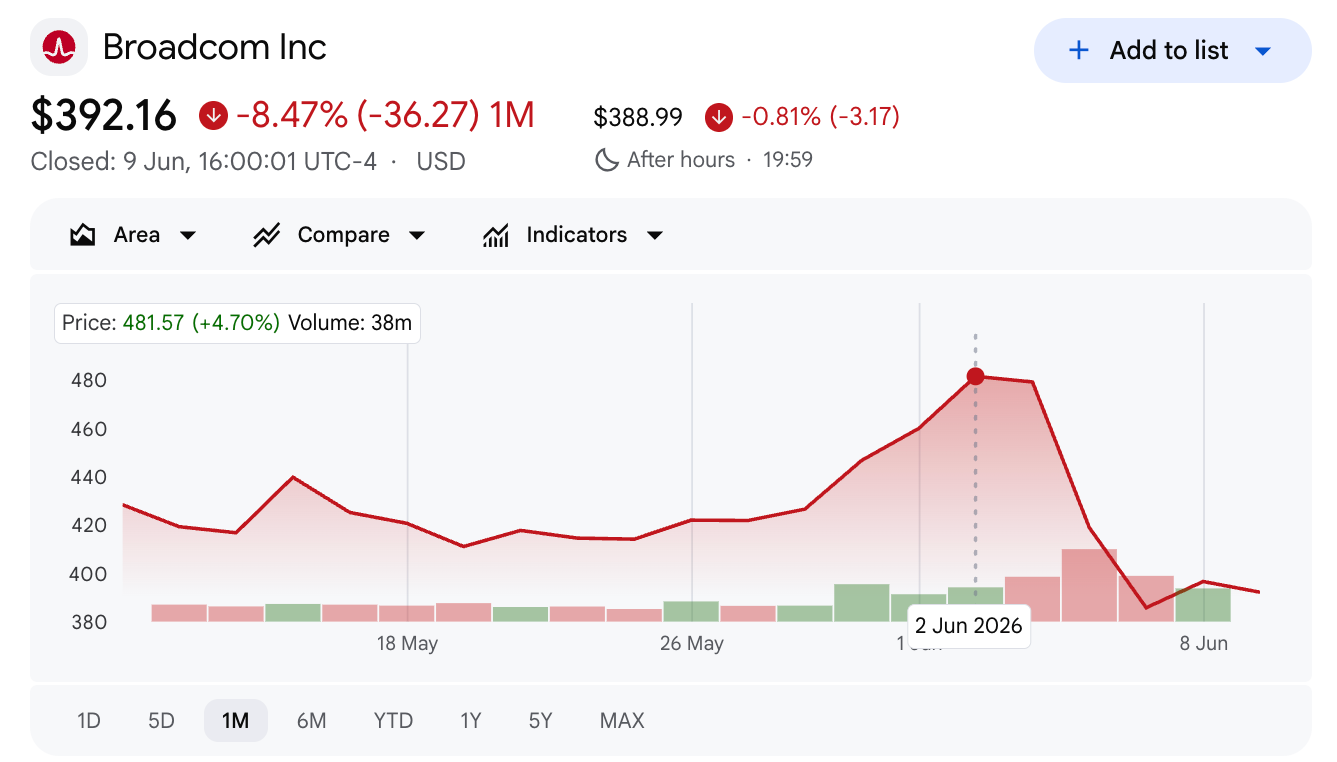
The stock spent most of the month going up and then lost a fifth of its value in under a week. The whole chip space went down with it. If you were holding it, you were not thinking about frameworks. You were staring at a red screen after lunch, asking the three questions every holder asks and no one answers in advance:
Is it my stock? Is it my sector? Or is the whole market breaking?
Here is the uncomfortable truth about investing content, including mine. We teach solved problems. Your portfolio produces unsolved ones.
That gap is not your fault. No writer can cover your problem before it happens. The market invents new ones faster than anyone can publish.
So this edition is different. I am not handing you a prompt for this situation. I am going to build the answer in front of you, the same evening the problem showed up, using a stock I had never researched in my life until this week. And then I am going to show you the part that actually matters: the method underneath, the one you will reuse next month on a problem nobody has written about yet.
Solved problems make you informed. Unsolved ones make you money. This is how you work on the unsolved kind.
Almost everything I make ends up here in the open, because a workflow you can’t see doesn’t make anyone a better investor. This edition is a paid one, the first time in a while I have published a problem-to-skill build end to end. The free half gives you the method, the live session, and every raw number. The paid half resolves the verdict and hands you the finished skill. If you’ve been waiting for a reason to upgrade, I’d pick this one.
I Already Wrote This Edition Once. It Could Not Help Me This Week.
In November I published an edition about exactly this situation. An Indian stock called Power Finance Corporation had dropped 8 percent while its sector barely moved, and I showed you how to diagnose whether the problem was the company, the sector, or the market. You can read the whole edition here.
That edition had a 600-word prompt. It asked you to download two CSV files from the Indian stock exchange first. Then you pasted everything into an AI and waited.
It worked. Readers ran it. I was proud of it.
This week I went back to it, and I saw it for what it was. A solved problem, frozen in place. The prompt knew the Indian market. It knew NSE data files. It knew nothing about Broadcom, US sector funds, or where American capital hides when it gets scared. My own prompt could not help me with my own framework.
That is the problem with prompts. A prompt is an answer. It answers the exact problem it was written for, and nothing else.
And investing problems do not repeat politely. They come back wearing a different ticker, in a different market, with the data living somewhere new. Whatever hits your portfolio next month will not match anyone’s template. Including mine.
So this time I am not handing you the answer. I am going to show you how the answer gets built. The whole thing took one evening.
I used Claude’s new model, Fable 5. You may have seen it called Mythos 5, it is the same model. And I ran it inside Claude Code, directly in the Claude desktop app. If you have the Claude app on your computer, you already have everything I used. No terminal. No installation. Open the app, and Claude Code sits right there next to Cowork. (If you want the heavier setup I personally run, terminal, Obsidian vault and all, that is its own edition here.)
What follows are the five instructions I typed, in order. Each one is plain English. Each one carries a principle you will reuse on problems I will never write about.
But first, the three questions everything hangs on:
Is my stock weak on its own?
Is my sector shifting?
Or is the whole market repricing?
Before I show you a single number, commit to an answer.

The Build, In Five Moves
What follows is the entire session, in order. Five instructions, typed in plain English, inside Claude Code in the Claude desktop app. Each move carries a principle. The principles are the edition. Broadcom is just the example.
The whole session is also here as an 8-minute recording, uncut, nothing edited out. My suggestion: read the five moves first, then come back and watch it once you know what you are looking at. The moment the data source dies and the model reroutes itself is worth seeing with your own eyes.
Watch for: the model designing the data plan from three questions, the data source dying and the self-reroute, the patch on 48 files, the verdict, and the skill being written at the end.Move One. State the problem, not a prompt.
In November I would have started by writing a prompt. Role, inputs, computation steps, output format, NA rules. Six hundred words before the AI did anything.
This time I typed this:
Tech is selling off this week and Broadcom has dropped around 20 percent in five days. I want to answer three questions: Is Broadcom weak on its own? Is the whole sector breaking down? And where is the money actually going? Before you do anything, tell me exactly what data you would need to answer these three questions properly, and where you would get it from.Notice what that last sentence does. It does not ask for analysis. It asks for the data plan. Most people skip this and jump straight to the answer. The data plan is where the quality gets decided.
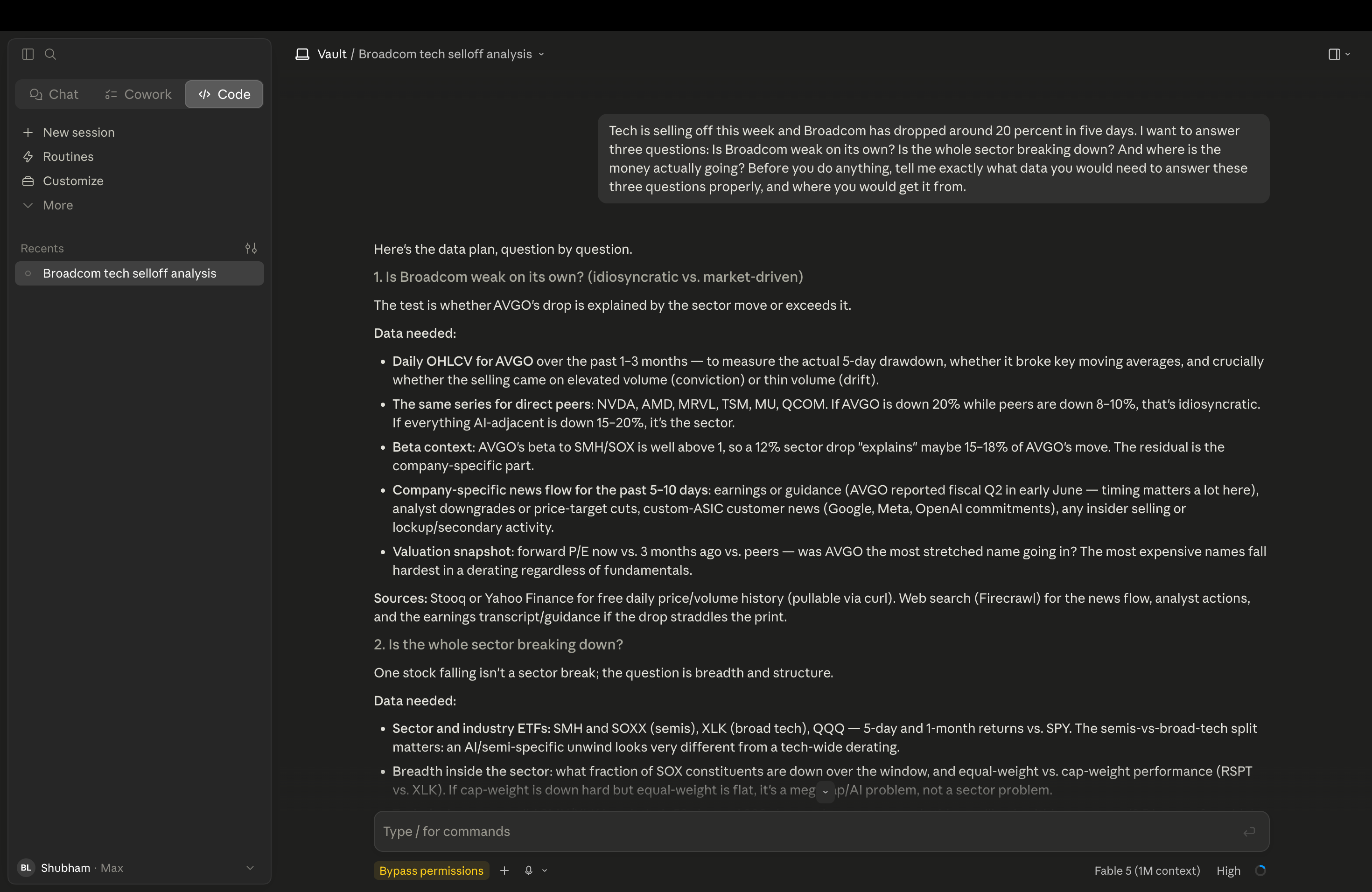
Full output:
What came back was a better research spec than my November prompt. For question one, it wanted Broadcom’s prices and volumes, the same series for six direct peers, and the news flow around the drop. Then it added something I had not asked for: beta context. Broadcom moves more than its sector on a normal day, so a sector drop already explains part of any Broadcom drop. The real question is the residual, the part the sector cannot explain.
For question two, it refused to judge a sector by one stock. It wanted breadth, what fraction of the chip names are actually down, and it wanted equal-weight versus cap-weight tech, because a megacap problem and a sector problem look identical in the headline index.
For question three, it opened with a caveat I want to frame: every share sold is a share bought. “Where is the money going” is really two measurable things, what is catching a bid, and where fund flows land. It flagged in advance that hard flow data lags by days and everything before that is inference from prices.
My November prompt had none of this reasoning. It had my instructions, frozen. This had thinking, because I handed it questions instead of commands.
The question I was actually asking in this move: what would I need to see to change my mind?
This framework exists for the moment a stock dips and panic takes over. If you know someone who lives that moment every correction, send them this edition, referrals earn you paid access.
Move Two. Files, not memory.
The single biggest source of AI errors in finance is letting the model carry numbers in its head. Numbers read off webpages, half-remembered from training, blended across dates. So the second instruction set one rule for the rest of the session:
Good. Pull all of it. Two rules. First, everything lands as files in a dated data folder: daily closing prices and volumes as CSVs going back about three months for every ticker and ETF you listed, and the news timeline and any ETF flow findings as a markdown file with the source of every item. Second, from here on, every number we use must come from these files, not from memory or a web page.Then I watched it work, and this is the part no demo video shows you, so I am leaving it in.
Its first-choice data source turned out to be blocked behind a JavaScript wall. It fell back to Yahoo Finance’s API, which rate-limited it. It fell back again, to the yfinance library, which worked. Then its integrity scan caught that Yahoo had not yet backfilled the previous day’s close, so the latest row of every file was empty. It patched all 48 US-listed series from a different endpoint, verified the dates, and documented the patch in a README. Then my Firecrawl ran out of credits mid news-pull and it switched to built-in web search without being told.
None of this was my plan. All of it is why the workflow survives contact with reality. Twenty minutes later the folder held 50 price files covering 64 trading days, a news timeline where every single item carries its source link, and a README documenting where every number came from, including the patch.
That folder is the product. Everything after this is just reading it. The full folder is in the repo:
The question I was actually asking in this move: when this analysis tells me something uncomfortable, what will I trust, and why?
Move Three. Models interpret. Code computes.
I had the third instruction ready in my notes. Here it is, exactly as I planned to type it:
Now compute from the files: returns over 1 day, 5 days, 1 month and 3 months for Broadcom, its sector benchmarks, all the major sector ETFs and the safe-haven assets. Also compute Broadcom’s return minus its sector’s return, 20-day volume z-scores for the sector’s top holdings, and sector breadth, meaning what percent of holdings are positive. Do all of it in code and save the result tables as files.I never got to type it.
The moment the data folder was full, the model went ahead and computed all of it on its own, in code, and saved the tables next to the prices. Not because it read my mind. Because the rule I set in Move Two, every number must come from these files, left it no other way to proceed. Set the architecture right and the discipline follows without being asked.
In November, the AI did this arithmetic in its head, reading numbers off pages and calculating returns as a language model, which is exactly where language models are weakest. The wall of warnings in my old prompt existed to compensate for that. This time the arithmetic never touched the model. A script ran on the folder. Same input, same output, every time.
Here is what the files say, and I am giving you the exact figures because every one of them traces to a CSV in the repo:
Broadcom fell 18.6 percent over the five days. Its sector fund, SMH, fell 6.5 percent. Broadcom’s beta to its sector, measured on the three months before the event, is 0.76, which means the sector’s week only explains a 4.9 percent drop. The residual, the Broadcom-specific part, is roughly 13.6 percentage points. And it happened on volume running at 2.2 times the three-month average. That is not drift. That is conviction selling.
The sector table is just as blunt. 22 of 25 chip names down on the week, median minus 6.3 percent. Equal-weight tech fell as much as cap-weight tech, 8.9 versus 8.8 percent, so this was not just a megacap story. And yet: every benchmark, SMH, SOXX, XLK, QQQ, SPY, still sits above its 50-day average. Every one except Broadcom itself.
The question I was actually asking in this move: which of these numbers would I bet money are correct? With computed files, the answer is all of them. With a chatbot’s mental math, I have never once been able to say that.
Below the line: the verdict on all three questions, the poll resolved, the moment the model audits my own rules and finds where they are blind, the fourth classification that did not exist this morning, where the money actually went, and the finished skill you can install and run on any stock you own.
